on
Let's Build a Simple Database
제1 장 - 소개 및 REPL 구축
이 글은 Connor Stack의 Let’s Build a Simple Database를 번역한 글입니다.
알림 : 부족한 실력 탓에 잘못된 번역, 부자연스러운 문장이 있을 수 있습니다. 해당 문제에 대한 의견을 댓글이나 GitHub 저장소 Pull Request를 통해 제안해 주시면 감사한 마음으로 적극 반영하도록 하겠습니다. 감사합니다.
웹 개발자로서, 매일 관계형 데이터베이스를 사용하지만, 작동원리를 이해하지는 못했습니다. 따라서 몇 가지 궁금증을 가지고 있었습니다.
- 데이터가 어떠한 형식으로 저장되는가? (메모리와 디스크에)
- 언제 메모리에서 디스크로 옮겨지는가?
- 왜 테이블마다 하나의 주키만을 가질 수 있는가?
- 어떻게 트랜잭션 롤백이 수행되는가?
- 인덱스는 어떻게 구성되는가?
- 전체 테이블 탐색(full table scan) 작업은 언제, 어떻게 수행되는가?
- 준비된 문장(prepared statement)은 어떠한 형식으로 저장되는가?
즉, 데이터베이스는 어떻게 작동 하는가?
궁금증을 해결하기 위해, 데이터베이스를 처음부터 만들어 볼 것입니다. MySQL이나 PostgreSQL 보다 적은 기능만으로 작게 설계된 sqlite를 본떠서 만들 것이며, 이 작업이 데이터베이스를 이해하는데 큰 도움이 될 것이라 생각합니다. 전체 데이터베이스는 하나의 파일에 작성합니다!
Sqlite
웹사이트에는 sqlite 내부 관련 문서가 많이 있습니다. 참고로, 필자는 SQLite Database System: Design and Implementation의 사본을 갖고 있습니다.
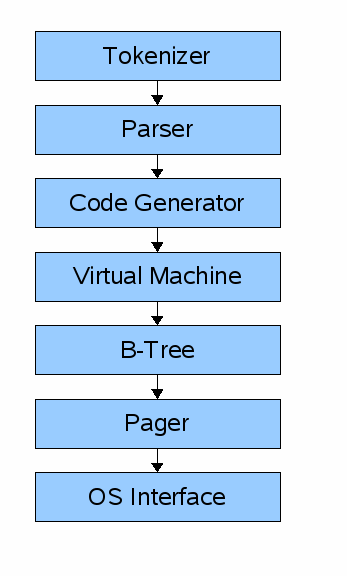 |
쿼리는 데이터를 가져오거나 수정하기 위해 구성 요소들의 사슬을 통과합니다. 전단부(front-end) 는 다음으로 구성됩니다.
- 토크나이저(tokenizer)
- 파서(parser)
- 코드 생성기(code generator)
전단부의 입력은 SQL 쿼리입니다. 출력은 sqlite 가상 머신 바이트코드 (기본적으로 데이터베이스에서 작동할 수 있는 컴파일된 프로그램)입니다.
후단부(back-end) 는 다음으로 구성됩니다.
- 가상 머신(virtual machine)
- B-트리(B-tree)
- 페이저(pager)
- 운영체제 인터페이스(os interface)
가상 머신(virtual machine) 은 전단부에서 생성된 바이트코드를 명령어로 받아들입니다. 그 후, B-tree 자료구조에 저장된 하나 이상의 테이블 혹은 인덱스를 대상으로 작업을 수행합니다. 기본적으로 가상 머신은 바이트 코드 명령어 유형에 따라 분기하는 큰 스위치 문입니다.
각각의 B-트리(B-tree) 는 많은 노드로 구성됩니다. 각 노드의 길이는 한 페이지입니다. B-tree는 페이저(pager)에게 명령하여, 디스크에서 페이지를 가져오거나 다시 디스크로 저장하도록 할 수 있습니다.
페이저(pager) 는 페이지의 데이터를 읽거나 페이지에 데이터를 쓰는 명령을 받습니다. 데이터베이스 파일에서 적절한 오프셋에 위치한 데이터를 읽거나 쓰는 역할을 수행합니다. 또한 최근 접근 페이지에 대한 캐시를 메모리에 유지하고, 캐시 속 페이지가 디스크에 다시 쓰이는 시기를 결정합니다.
운영체제 인터페이스(os interface) 는 sqlite가 컴파일된 운영체제에 따라 다른 층입니다. 여기서는 멀티 플랫폼을 지원하지는 않을 것입니다.
천 리 길도 한 걸음부터, 그러므로 간단한 것부터 시작해보겠습니다.
간단한 REPL 만들기
Sqlite를 명령줄에서 실행시키면, 입력-실행-출력 루프를 시작합니다.
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~
이 작업을 위해, 메인 함수는 프롬프트를 출력하고, 한 줄의 입력을 가져오며 입력을 처리하는 무한 루프를 가질 것입니다.
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
먼저, getline() 함수와 상호작용하는데 필요한 정보들을 하나로 감싼 InputBuffer 를 정의합니다. (자세한 설명은 잠시 후에 하겠습니다.)
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
다음으로, 프롬프트를 사용자에게 출력하는 print_prompt() 를 정의합니다. 입력받기 전에 이 작업을 먼저 수행합니다.
void print_prompt() { printf("db > "); }
입력의 한 줄을 읽어오기 위해, getline() 을 사용합니다.
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
lineptr : 입력 저장 버퍼를 가리키는 포인터 변수의 포인터입니다. NULL 로 설정된 경우 함수 수행이 실패하더라도, getline 에 의해서 동적 메모리 할당이 되므로 사용자가 해제해야 합니다.
n : 할당된 버퍼의 크기를 갖는 변수의 포인터입니다.
stream : 읽어 올 입력 스트림 입니다. 여기서는, 표준 입력을 사용합니다.
return value : 읽어온 바이트 수로서, 버퍼의 크기보다 작을 수도 있습니다.
우리는 getline 함수에게 input_buffer->buffer 에 입력 줄을 저장하고 할당된 버퍼의 크기를 input_buffer->buffer_length 에 저장하도록 지시합니다. 반환 값은 input_buffer->input_length 에 저장합니다.
buffer는 null로 초기화해서, getline 이 입력 줄을 저장하기에 충분한 버퍼를 동적 할당하고, 할당받은 버퍼를 buffer 가 가리키도록 합니다.
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// 후행 줄 바꿈 제거
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
이제 InputBuffer * 인스턴스가 할당받은 메모리 공간과 구조체의 buffer 요소를 해제하는 함수를 정의합니다. (getline 함수는 read_input 함수에서 input_buffer->buffer 에 대한 메모리를 동적 할당 합니다.)
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
최종적으로, 명령어를 분석하고 실행합니다. 현재는 하나의 인식 가능한 명령어 .exit 만 존재합니다. 이 명령은 프로그램을 종료시킵니다. 나머지 명령은 에러 메시지를 출력하고 루프를 계속 진행합니다.
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
실행해 봅시다!
~ ./db
db > .tables
Unrecognized command '.tables'.
db > .exit
~
좋습니다, 잘 작동하는 REPL을 만들었습니다. 다음 장에서, 우리의 명령어 개발을 시작하겠습니다. 이번 장의 전체 코드는 아래에 있습니다.
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// 후행 줄 바꿈 제거
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
Discussion and feedback