on
Let's Build a Simple Database
제13 장 - 분할 후 부모 노드 갱신
이 글은 Connor Stack의 Let’s Build a Simple Database를 번역한 글입니다.
알림 : 부족한 실력 탓에 잘못된 번역, 부자연스러운 문장이 있을 수 있습니다. 해당 문제에 대한 의견을 댓글이나 GitHub 저장소 Pull Request를 통해 제안해 주시면 감사한 마음으로 적극 반영하도록 하겠습니다. 감사합니다.
B-트리 구현 여정의 다음 단계로, 단말 노드 분할 후 부모 노드를 갱신하는 작업을 진행하겠습니다. 다음 예제를 참조하여 진행하겠습니다.
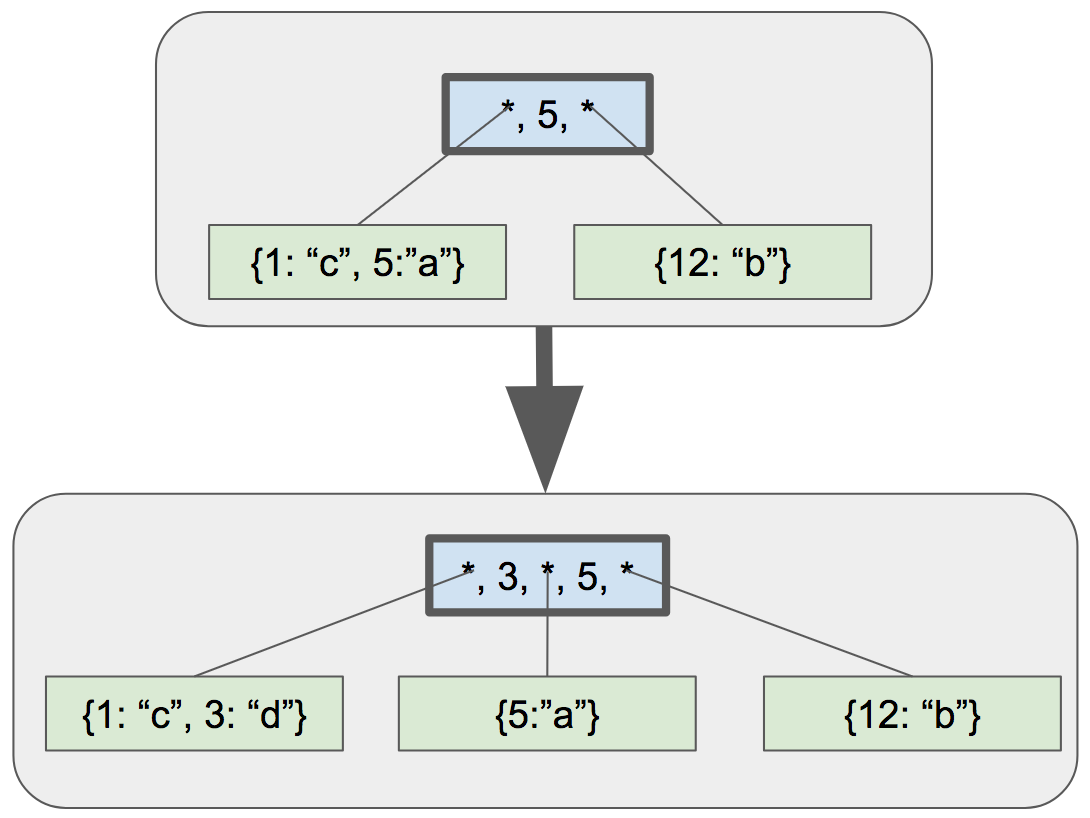 |
이 예에서는 키 “3” 을 트리에 추가합니다. 키 추가로 왼쪽 단말 노드는 분할됩니다. 분할 후 다음 절차를 수행하여 트리를 갱신합니다.
- 부모 노드의 첫 번째 키를 왼쪽 자식 노드의 최대 키값(“3”)으로 갱신합니다.
- 갱신된 키 뒤에 새로운 자식 포인터 / 키 쌍 추가합니다.
- 새로운 자식 포인터는 새로운 자식 노드를 가리킵니다.
- 새 키는 새 자식 노드의 최대 키값(“5”)입니다.
무엇보다 먼저, 스텁 코드를 두 가지 새로운 함수 호출로 교체합니다. update_internal_node_key() 는 1번 절차, internal_node_insert() 는 2번 절차에 해당합니다.
@@ -670,9 +725,11 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
*/
void* old_node = get_page(cursor->table->pager, cursor->page_num);
+ uint32_t old_max = get_node_max_key(old_node);
uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
void* new_node = get_page(cursor->table->pager, new_page_num);
initialize_leaf_node(new_node);
+ *node_parent(new_node) = *node_parent(old_node);
*leaf_node_next_leaf(new_node) = *leaf_node_next_leaf(old_node);
*leaf_node_next_leaf(old_node) = new_page_num;
@@ -709,8 +766,12 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
if (is_node_root(old_node)) {
return create_new_root(cursor->table, new_page_num);
} else {
- printf("Need to implement updating parent after split\n");
- exit(EXIT_FAILURE);
+ uint32_t parent_page_num = *node_parent(old_node);
+ uint32_t new_max = get_node_max_key(old_node);
+ void* parent = get_page(cursor->table->pager, parent_page_num);
+
+ update_internal_node_key(parent, old_max, new_max);
+ internal_node_insert(cursor->table, parent_page_num, new_page_num);
+ return;
}
}
부모 노드에 대한 참조를 얻기 위해, 각 노드의 부모 포인터 필드가 부모 노드를 가리키도록 설정해야 합니다.
+uint32_t* node_parent(void* node) { return node + PARENT_POINTER_OFFSET; }
@@ -660,6 +675,48 @@ void create_new_root(Table* table, uint32_t right_child_page_num) {
uint32_t left_child_max_key = get_node_max_key(left_child);
*internal_node_key(root, 0) = left_child_max_key;
*internal_node_right_child(root) = right_child_page_num;
+ *node_parent(left_child) = table->root_page_num;
+ *node_parent(right_child) = table->root_page_num;
}
이제 부모 노드에서 갱신될 셀을 찾아야 합니다. 자식 노드는 자신의 페이지 번호를 알지 못하므로, 이를 이용해서 갱신될 셀을 찾을 수는 없습니다. 하지만 자신이 갖는 최대 키값은 알고 있기 때문에, 최대 키를 이용해서 부모 노드에서 갱신될 셀의 위치를 찾을 수 있습니다.
+void update_internal_node_key(void* node, uint32_t old_key, uint32_t new_key) {
+ uint32_t old_child_index = internal_node_find_child(node, old_key);
+ *internal_node_key(node, old_child_index) = new_key;
}
internal_node_find_child() 내부에서는 내부 노드에서 키를 찾는데 사용하던 코드를 재사용 하겠습니다. 새로운 헬퍼 함수를 사용해서 internal_node_find() 의 개선도 진행합니다.
-Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
- void* node = get_page(table->pager, page_num);
+uint32_t internal_node_find_child(void* node, uint32_t key) {
+ /*
+ 주어진 키를 포함하는 자식 노드의
+ 인덱스를 반환합니다.
+ */
+
uint32_t num_keys = *internal_node_num_keys(node);
- /* 이진 탐색으로 탐색할 자식의 인덱스를 찾습니다. */
+ /* 이진 탐색 */
uint32_t min_index = 0;
uint32_t max_index = num_keys; /* 키 개수 + 1 개의 자식 노드가 있습니다. */
@@ -386,7 +394,14 @@ Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
}
}
- uint32_t child_num = *internal_node_child(node, min_index);
+ return min_index;
+}
+
+Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
+ void* node = get_page(table->pager, page_num);
+
+ uint32_t child_index = internal_node_find_child(node, key);
+ uint32_t child_num = *internal_node_child(node, child_index);
void* child = get_page(table->pager, child_num);
switch (get_node_type(child)) {
case NODE_LEAF:
이제 이번 장의 핵심인 internal_node_insert() 를 구현합니다. 한 부분 씩 설명하겠습니다.
+void internal_node_insert(Table* table, uint32_t parent_page_num,
+ uint32_t child_page_num) {
+ /*
+ 새로운 자식/키 쌍을 적절한 위치에 추가합니다.
+ */
+
+ void* parent = get_page(table->pager, parent_page_num);
+ void* child = get_page(table->pager, child_page_num);
+ uint32_t child_max_key = get_node_max_key(child);
+ uint32_t index = internal_node_find_child(parent, child_max_key);
+
+ uint32_t original_num_keys = *internal_node_num_keys(parent);
+ *internal_node_num_keys(parent) = original_num_keys + 1;
+
+ if (original_num_keys >= INTERNAL_NODE_MAX_CELLS) {
+ printf("Need to implement splitting internal node\n");
+ exit(EXIT_FAILURE);
+ }
새로운 셀(자식/키 쌍)이 삽입되어야 할 인덱스는 새로운 자식 노드의 최대 키에 따라 달라집니다. 위의 예를 보면, child_max_key 는 5가 되고 index 는 1이 됩니다.
내부 노드에 새 셀을 삽입할 공간이 없다면 에러를 발생합니다. 그 부분은 나중에 구현하겠습니다.
이제 함수의 나머지 부분을 살펴보겠습니다.
+
+ uint32_t right_child_page_num = *internal_node_right_child(parent);
+ void* right_child = get_page(table->pager, right_child_page_num);
+
+ if (child_max_key > get_node_max_key(right_child)) {
+ /* 오른쪽 자식 교체 */
+ *internal_node_child(parent, original_num_keys) = right_child_page_num;
+ *internal_node_key(parent, original_num_keys) =
+ get_node_max_key(right_child);
+ *internal_node_right_child(parent) = child_page_num;
+ } else {
+ /* 새로운 셀을 위한 공간 생성 */
+ for (uint32_t i = original_num_keys; i > index; i--) {
+ void* destination = internal_node_cell(parent, i);
+ void* source = internal_node_cell(parent, i - 1);
+ memcpy(destination, source, INTERNAL_NODE_CELL_SIZE);
+ }
+ *internal_node_child(parent, index) = child_page_num;
+ *internal_node_key(parent, index) = child_max_key;
+ }
+}
우리는 가장 오른쪽의 자식 포인터를 나머지 자식/키 쌍 들과 분리하여 저장했기 때문에, 새로운 자식이 가장 오른쪽 자식이 되는 경우를 다르게 처리해 줘야 합니다.
우리의 예는 else 블록으로 분기합니다. 가장 먼저 다른 셀들을 오른쪽으로 한 칸씩 옮겨 새로운 셀을 위한 공간을 만듭니다. (하지만 예제에서 이동이 필요한 셀들은 없습니다.)
다음으로, 새로운 자식 포인터와 키 쌍을 index 로 결정된 셀에 저장합니다.
테스트 케이스 크기를 줄이기 위해 INTERNAL_NODE_MAX_CELLS 을 하드코딩하여 설정하겠습니다.
@@ -126,6 +126,8 @@ const uint32_t INTERNAL_NODE_KEY_SIZE = sizeof(uint32_t);
const uint32_t INTERNAL_NODE_CHILD_SIZE = sizeof(uint32_t);
const uint32_t INTERNAL_NODE_CELL_SIZE =
INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE;
+/* 테스트를 위해 작게 설정했습니다. */
+const uint32_t INTERNAL_NODE_MAX_CELLS = 3;
테스트 결과, 우리의 대량 데이터 테스트는 오래된 스텁 코드를 통과하여 새로운 스텁 코드 출력을 얻게 됩니다.
@@ -65,7 +65,7 @@ describe 'database' do
result = run_script(script)
expect(result.last(2)).to match_array([
"db > Executed.",
- "db > Need to implement updating parent after split",
+ "db > Need to implement splitting internal node",
])
매우 만족스럽습니다.
4개 단말 노드 트리를 출력하는 또 다른 테스트를 추가하겠습니다. 이 테스트는 무작위로 추출된 순서의 레코드를 삽입해서 순차적인 삽입 보다 많은 경우를 테스트합니다.
+ it 'allows printing out the structure of a 4-leaf-node btree' do
+ script = [
+ "insert 18 user18 person18@example.com",
+ "insert 7 user7 person7@example.com",
+ "insert 10 user10 person10@example.com",
+ "insert 29 user29 person29@example.com",
+ "insert 23 user23 person23@example.com",
+ "insert 4 user4 person4@example.com",
+ "insert 14 user14 person14@example.com",
+ "insert 30 user30 person30@example.com",
+ "insert 15 user15 person15@example.com",
+ "insert 26 user26 person26@example.com",
+ "insert 22 user22 person22@example.com",
+ "insert 19 user19 person19@example.com",
+ "insert 2 user2 person2@example.com",
+ "insert 1 user1 person1@example.com",
+ "insert 21 user21 person21@example.com",
+ "insert 11 user11 person11@example.com",
+ "insert 6 user6 person6@example.com",
+ "insert 20 user20 person20@example.com",
+ "insert 5 user5 person5@example.com",
+ "insert 8 user8 person8@example.com",
+ "insert 9 user9 person9@example.com",
+ "insert 3 user3 person3@example.com",
+ "insert 12 user12 person12@example.com",
+ "insert 27 user27 person27@example.com",
+ "insert 17 user17 person17@example.com",
+ "insert 16 user16 person16@example.com",
+ "insert 13 user13 person13@example.com",
+ "insert 24 user24 person24@example.com",
+ "insert 25 user25 person25@example.com",
+ "insert 28 user28 person28@example.com",
+ ".btree",
+ ".exit",
+ ]
+ result = run_script(script)
출력은 다음과 같습니다.
- internal (size 3)
- leaf (size 7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- key 1
- leaf (size 8)
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- key 15
- leaf (size 7)
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- key 22
- leaf (size 8)
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
db >
잘 보면 버그가 보입니다.
- 5
- 6
- 7
- key 1
키는 1이 아닌 7이어야 합니다!
여러 번의 디버깅 끝에, 필자는 잘못된 포인터 산술 연산이 원인임 찾아냈습니다.
uint32_t* internal_node_key(void* node, uint32_t key_num) {
- return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+ return (void*)internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
}
INTERNAL_NODE_CHILD_SIZE 는 4입니다. 필자의 의도는 internal_node_cell() 의 결과에 4 바이트를 더하는 것입니다. 하지만 internal_node_cell() 는 uint32_t* 를 반환하므로 4 * sizeof(uint32_t) 가 더해지게 됩니다. 산술 연산 전에 void* 로 캐스팅하여 문제를 해결했습니다.
주의! void 포인터의 산술 연산을 C 표준이 아니므로 컴파일러에 따라 작동하지 않을 수도 있습니다. 향후에 이식 관련된 글을 쓰게 될 것이니, 지금은 void 포인터 연산으로 남겨 두겠습니다.
좋습니다. 완전완 B-트리 구현을 위해 한 걸음 더 나아갔습니다. 다음 단계는 내부 노드를 분할하는 것입니다. 그럼 다음 장에서 뵙겠습니다.
Discussion and feedback