on
Let's Build a Simple Database
제5 장 - 디스크 지속성
이 글은 Connor Stack의 Let’s Build a Simple Database를 번역한 글입니다.
알림 : 부족한 실력 탓에 잘못된 번역, 부자연스러운 문장이 있을 수 있습니다. 해당 문제에 대한 의견을 댓글이나 GitHub 저장소 Pull Request를 통해 제안해 주시면 감사한 마음으로 적극 반영하도록 하겠습니다. 감사합니다.
“세상에서 끈기를 대신할 수 있는 것은 없다.” – 캘빈 쿨리지
우리의 데이터베이스가 레코드를 삽입하고 다시 읽어 올수 있게 되었습니다. 단, 프로그램이 계속 실행 중이어야만 합니다. 만약 프로그램을 종료하고 다시 시작한다면, 모든 레코드는 사라지게 됩니다. 우리는 다음과 같이 작동하길 원합니다.
it 'keeps data after closing connection' do
result1 = run_script([
"insert 1 user1 person1@example.com",
".exit",
])
expect(result1).to match_array([
"db > Executed.",
"db > ",
])
result2 = run_script([
"select",
".exit",
])
expect(result2).to match_array([
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
sqlite처럼 전체 데이터베이스를 파일에 저장하여 레코드가 지속되도록 해보겠습니다.
우리는 페이지 크기의 메모리 블록으로 행을 직렬화 하였습니다. 이는 파일 저장 작업을 위한 준비를 이미 마친 것입니다. 지속성 추가를 위해서는, 단순히 메모리의 블록들을 파일에 쓰고 프로그램 시작 시 다시 읽어 오면 될 것입니다.
좀 더 쉽게 하기 위해, 페이저라는 추상 객체를 만들겠습니다. 우리는 페이저에게 페이지 번호 x를 요청하고, 페이저는 메모리의 블록을 돌려줍니다. 페이저는 먼저 캐시를 탐색합니다. 캐시 미스가 발생하는 경우, 디스크에서 메모리로 블록을 복사합니다. (데이터베이스 파일을 읽음으로써)
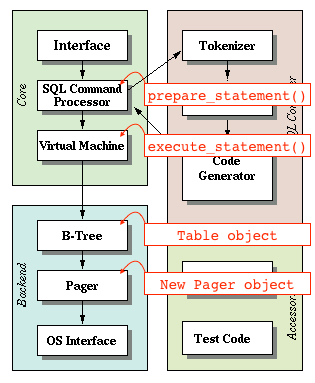 |
페이저는 페이지 캐시와 파일에 접근합니다. 테이블 객체는 페이저를 통해 페이지들을 요청합니다.
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
uint32_t num_rows;
} Table;
이제 new_table() 함수가 데이터베이스에 대한 연결을 여는 기능을 갖기 때문에 함수의 이름을 db_open() 으로 변경합니다. 연결을 여는 것은 다음을 뜻합니다.
- 데이터베이스 파일을 엽니다.
- 페이저 데이터 구조를 초기화합니다.
- 테이블 데이터 구조를 초기화합니다.
-Table* new_table() {
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+ table->pager = pager;
+ table->num_rows = num_rows;
return table;
}
db_open() 내부에서는 데이터 베이스 파일을 열고 파일의 크기를 확인하는 pager_open() 을 호출합니다. pager_open() 은 모든 페이지 캐시를 NULL로 초기화합니다.
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // 읽기/쓰기 모드
+ O_CREAT, // 파일이 존재하지 않으면 파일 생성
+ S_IWUSR | // 사용자 쓰기 권한
+ S_IRUSR // 사용자 읽기 권한
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ pager->pages[i] = NULL;
+ }
+
+ return pager;
+}
페이저 추상화를 위해, 페이지를 가져오는 로직을 하나의 함수로 생성합니다.
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = table->pages[page_num];
- if (page == NULL) {
- // 페이지에 접근하는 경우 메모리 할당
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void* page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
get_page() 는 캐시 미스를 처리하는 로직을 갖습니다. 페이지는 데이터베이스 파일에 순서대로 저장된다고 가정합니다. (0번 페이지 오프셋 : 0, 1번 페이지 오프셋 : 4096, 2번 페이지 오프셋 : 8192 …) 요청된 페이지가 파일의 범위를 벗어나는 경우, 아무것도 없음을 알기 때문에, 메모리 공간만 할당하고 반환하면 됩니다. 이 공간은 나중에 캐시를 디스크에 플러시 할 때 파일에 추가됩니다.
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // 캐시 미스. 메모리를 할당하고 파일에서 읽어옵니다.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // 파일의 끝에 불완전한 페이지를 저장할 수도 있습니다.
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
현재는, 사용자가 데이터베이스 연결을 종료 할때 까지 캐시를 디스크에 플러시 하지 않고 기다립니다. 이제 사용자가 종료할 때 db_close() 라는 새로운 함수를 호출하도록 만들어 보겠습니다. 새로운 함수는 다음을 수행합니다.
- 페이지 캐시를 디스크에 플러시 합니다.
- 데이터베이스 파일을 닫습니다.
- 페이저와 테이블 구조의 메모리를 해제합니다.
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // 파일의 끝에 불완전한 페이지를 저장할 수도 있습니다.
+ // B-트리로 전환하면 이 작업은 필요하지 않게 됩니다.
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+ free(pager);
+ free(table);
+}
+
-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
현재 설계에서는, 파일의 길이로 데이터베이스에 몇 개의 행이 있는지 계산합니다. 그래서 파일 끝에 불완전한 페이지를 저장해야만 합니다. 이는 pager_flush() 가 페이지 번호와 크기를 함께 매개 변수로 갖는 이유입니다. 좋은 설계는 아니며, B-트리 구현을 시작하면 금방 사라질 것입니다.
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written =
+ write(pager->file_descriptor, pager->pages[page_num], size);
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
마지막으로 파일명을 명령행 인자로 받아들여야 합니다. 또한 do_meta_command 에 인자를 추가해야 합니다.
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
- switch (do_meta_command(input_buffer)) {
+ switch (do_meta_command(input_buffer, table)) {
개선을 통해, 데이터베이스를 닫고 다시 열수 있으며, 입력한 레코드들도 그대로 남게 됩니다!
~ ./db mydb.db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 voltorb volty@example.com
Executed.
db > .exit
~
~ ./db mydb.db
db > select
(1, cstack, foo@bar.com)
(2, voltorb, volty@example.com)
Executed.
db > .exit
~
추가로 재미 삼아 mydb.db 를 통해 데이터가 어떻게 저장되고 있는지 살펴보겠습니다. vim을 16진수 편집기로 사용하여 파일의 메모리 레이아웃을 살펴보겠습니다.
vim mydb.db
:%!xxd
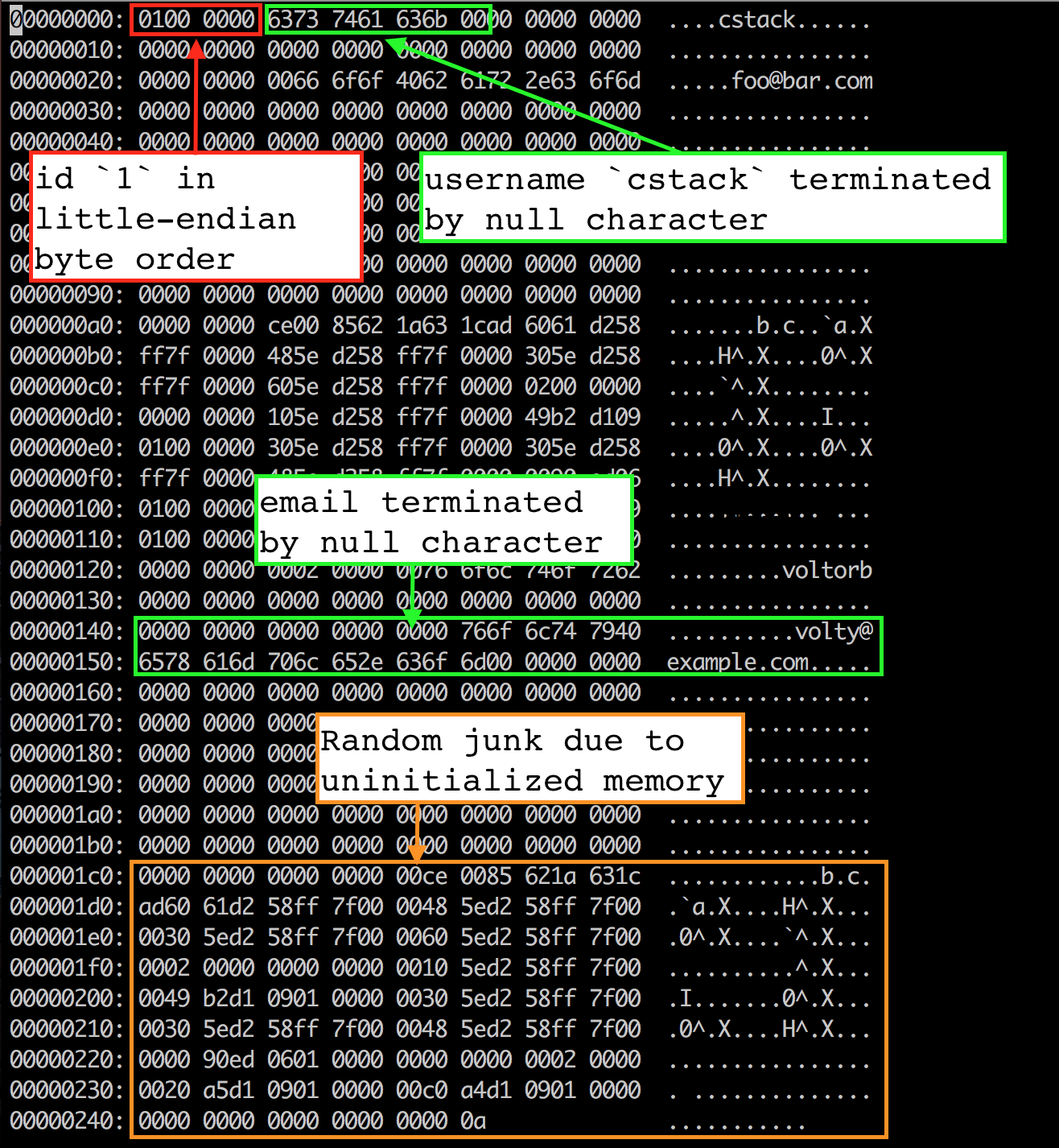 |
첫 4 바이트는 첫 번째 행의 id입니다. (uint32_t 를 사용함으로 4바이트입니다.) 리틀 엔디안 순서로 저장되어서, 최하위 바이트 (01) 가 먼저 나오고 상위 바이트 (00 00 00) 가 따라오게 됩니다. Row 구조체를 페이지 캐시로 복사할 때 memcpy() 를 사용하였습니다. 따라서 구조체는 리틀 엔디안 순서로 메모리에 저장됩니다. 이것은 필자가 프로그램 컴파일에 사용한 머신의 특성입니다. 만약 필자의 머신에서 작성된 데이터베이스 파일을 다른 빅 엔디안 머신에서 읽으려면, serialize_row() 와 deserialize_row() 함수가 항상 동일한 방식의 저장 방식을 사용하도록 수정해야 합니다.
다음 33 바이트는 사용자 이름을 null 종료 문자열로 저장합니다. 보이는 것처럼, “cstack” 은 ASCII 16진수 값으로 63 73 74 61 63 6b 이며 null 문자 (00) 가 따라옵니다. 33 바이트 중 나머지는 사용되지 않습니다.
다음 256 바이트는 동일한 방식으로 저장된 이메일 정보입니다. 여기를 보면, null 문자 이후에 랜덤 한 쓰레기 값을 볼 수 있습니다. 이는 메모리에서 Row 구조체를 초기화하지 않아 발생합니다. 우리는 문자열이 아닌 값들도 함께 포함된 256 바이트의 이메일 버퍼 전체를 파일에 복사한 것입니다. 따라서, 구조체 할당 전에 있던 무언가의 값이 그대로 기록된 것입니다. 하지만 null 종료 문자를 사용하기 때문에 작동에 영향을 미치지는 않았습니다.
참고: 모든 바이트를 초기화하려면, serialize_row 에서 username 과 email 필드를 복사할 때 memcpy 대신 strncpy 를 사용하면 됩니다.
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);
+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);
}
결론
좋습니다! 이제 지속성을 갖게 되었습니다. 하지만 훌륭하진 않습니다. 예를 들어 .exit 를 입력하지 않고 프로그램을 종료하는 경우 변경 내용이 손실됩니다. 또한 디스크에서 읽은 이후 변경되지 않은 페이지까지 디스크에 저장하고 있습니다. 이러한 문제들은 차후에 다루겠습니다.
다음 장에서는 커서를 소개하겠습니다. 커서를 통해 B-트리를 쉽게 구현할 수 있을 것입니다.
다음 장에서 뵙겠습니다!
변경된 부분
+#include <errno.h>
+#include <fcntl.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
+#include <unistd.h>
struct InputBuffer_t {
char* buffer;
@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
uint32_t num_rows;
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
} Table;
@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // 캐시 미스. 메모리를 할당하고 파일에서 읽어옵니다.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // 파일의 끝에 불완전한 페이지를 저장할 수도 있습니다.
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
+
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = table->pages[page_num];
- if (page == NULL) {
- // 페이지에 접근하는 경우 메모리 할당
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
-Table* new_table() {
- Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // 읽기/쓰기 모드
+ O_CREAT, // 파일이 존재하지 않으면 파일 생성
+ S_IWUSR | // 사용자 쓰기 권한
+ S_IRUSR // 사용자 읽기 권한
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
- table->pages[i] = NULL;
+ pager->pages[i] = NULL;
}
- return table;
+
+ return pager;
}
-void free_table(Table* table) {
- for (int i = 0; table->pages[i]; i++) {
- free(table->pages[i]);
- }
- free(table);
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
+ Table* table = malloc(sizeof(Table));
+ table->pager = pager;
+ table->num_rows = num_rows;
+
+ return table;
}
InputBuffer* new_input_buffer() {
@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,
+ SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written = write(
+ pager->file_descriptor, pager->pages[page_num], size
+ );
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
+
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // 파일의 끝에 불완전한 페이지를 저장할 수도 있습니다.
+ // B-트리로 전환하면 이 작업은 필요하지 않게 됩니다.
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+
+ free(pager);
+ free(table);
+}
+
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
- free_table(table);
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
return PREPARE_SUCCESS;
}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) {
}
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
그리고 변경된 테스트들입니다.
describe 'database' do
+ before do
+ `rm -rf test.db`
+ end
+
def run_script(commands)
raw_output = nil
- IO.popen("./db", "r+") do |pipe|
+ IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
@@ -28,6 +32,27 @@ describe 'database' do
])
end
+ it 'keeps data after closing connection' do
+ result1 = run_script([
+ "insert 1 user1 person1@example.com",
+ ".exit",
+ ])
+ expect(result1).to match_array([
+ "db > Executed.",
+ "db > ",
+ ])
+
+ result2 = run_script([
+ "select",
+ ".exit",
+ ])
+ expect(result2).to match_array([
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
Discussion and feedback